CS194 Project 4
Classification and Segmentation
Xuxin Cheng CS194-agv
Part 1: Image Classification
1.1 Network Structure
The original data is first normalized to [-1, 1] and then fed into the CNN.
| Layer | Kernel size | Input dimension | Output dimension |
|---|---|---|---|
| conv1 | 5 | n12828 | n322828 |
| max pool | 2 | n322828 | n321414 |
| conv2 | 5 | n321414 | n321414 |
| max pool | 2 | n321414 | n3277 |
| fully connected layer 1 | - | n(3277) | n64 |
| fully connected layer 2 | - | n64 | 10 |
*n is the batchsize
1.2 Hyperparameters
| Learning rate | Batch size | Number of epochs | L2 regularization weight |
|---|---|---|---|
| 0.0007 | 64 | 40 | 0.001 |
1.3 Results
1.3.1 Losses and Accuray
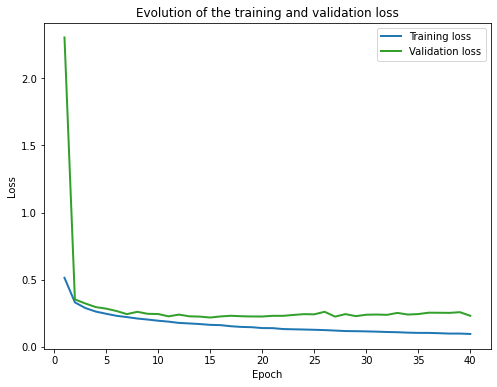 | 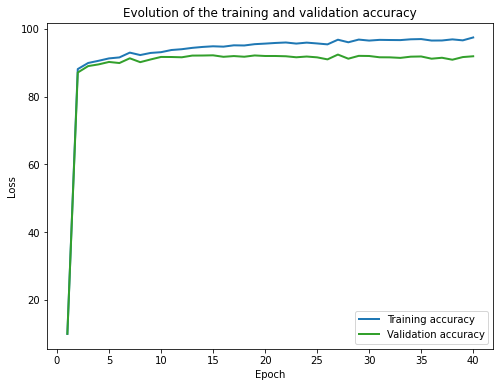 |
|---|---|
1.3.2 Class accuracy
| Class | Accuracy(%) |
|---|---|
| T-shirt | 83.50 |
| Trouser | 98.30 |
| Pullover | 90.00 |
| Dress | 92.30 |
| Coat | 91.00 |
| Sandal | 98.10 |
| Shirt | 71.60 |
| Sneaker | 98.40 |
| Bag | 97.80 |
| Ankle_boot | 95.00 |
We can see that the class "shirt" is the hardest to get. An explanation is that a shirt is too similar to a T-shirt. And we can see that the accuracy of "T-shirt" is the 2nd lowest because the network is confusing about these two classes.

1.3.3 Filter visualization
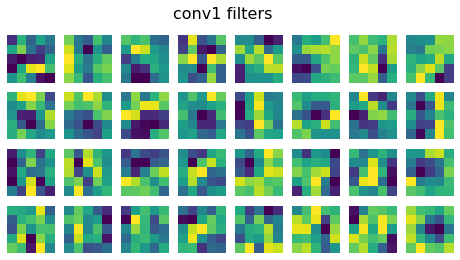

*the visualization of conv2 is by concatenating all 32x32 channels of 5x5 2d filter, as described here.
Part 2: Semantic Segmentation
2.1 Network Structure
The net work sturcture is shown in the following table. The parameters of conv_transpose layer are computed as
where is the ouput size; is stride; is input size; is padding and is kernel size.
| Layer | Kernel size | Padding | Stride | Input dimension | Output dimension |
|---|---|---|---|---|---|
| conv1 | 5 | 2 | 1 | n1256256 | n64256256 |
| max pool | 2 | - | - | n64256256 | n64128128 |
| conv2 | 3 | 1 | 1 | n64128128 | n128128128 |
| max pool | 2 | - | - | n128128128 | n1286464 |
| conv3 | 3 | 1 | 1 | n1286464 | n2566464 |
| max pool | 2 | - | - | n2566464 | n2563232 |
| conv_transpose1 | 4 | 1 | 2 | n2563232 | n1286464 |
| conv_transpose2 | 4 | 1 | 2 | n1286464 | n64128128 |
| conv_transpose3 | 4 | 1 | 2 | n64128128 | n16256256 |
| conv4 | 1 | 0 | 1 | n16256256 | n5256256 |
I got inspiration of network structure from this paper.
1.2 Hyperparameters
| Learning rate | Batch size | Number of epochs | L2 regularization weight |
|---|---|---|---|
| 1e-3 | 16 | 80 | 1e-3 |
1.3 Results
1.3.1 Losses and accuracy
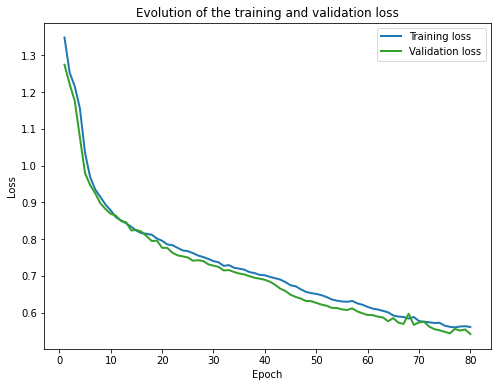
I found there was not a significant improvement of AP between epoch 40 and epoch 80. So I stopped training at epoch 80.
| Class | Color | Average Precision |
|---|---|---|
| others | black | 0.6849 |
| facade | blue | 0.7916 |
| pillar | green | 0.2269 |
| window | orange | 0.8432 |
| balcony | red | 0.5738 |
| Average AP | 0.6241 |
1.3.2 Some expamples
 |  |  |
|---|---|---|
 | 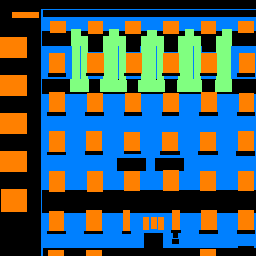 |  |
From the statistics and image results we can see that the network does not work well on pillars and balcony.